When we think about “information technology”, the images that might come to mind are of lines of code flashing quickly across a screen, a future in which artificial intelligence abounds, and incredible virtual images so realistically rendered that we cannot distinguish them from reality itself. But for all this to happen, computers have to deal with pedestrian tasks as well. In fact, computer science is nothing other than the study of all the subtasks that lie behind any algorithm, simple or advanced. Of these tasks, we will now spend some time looking at something a computer can do in the blink of an eye, yet the average child finds to be a total nightmare: putting things in order or sorting.

Interestingly, within the term “to sort” lie two hidden meanings that require very different approaches when addressing them. The first is the more obvious meaning of putting things in order: to receive a bunch of data and put them in sequence (order) following a given pattern. For example, teachers may have given a lot of exams and they need to order the completed tests alphabetically by last name. It is a different problem if what we want to do is keep the prescribed order over a longer period of time. By way of example, let’s consider a library where all the books are currently organized in a particular way (they are “ordered” or “sorted”). When a new batch of books arrives, librarians are responsible for putting the new entries in the appropriate place, respecting the pre-existing order. This second problem happens more frequently in computers (for example, databases tend to be saved once they have been structured) than in “real life” where chaos tends to take over when given the opportunity.
In this article, we will focus on the first problem. The scenario is always the same: a computer receives a bunch of data and for each pair of data it knows which should be positioned before the other. This approach is a way of abstracting the problem for us; it is equally valid if we are organizing numbers or if we are arranging people by their last names. What is important is which data element “comes before” the others. The result must always be a sequence of the elements themselves, but properly arranged. It is fascinating that for a problem that is so easy to explain, there aren’t just one or two algorithms, but dozens. We will explain a few of them here

The journey is made step by step
The first two algorithms that we will talk about deal with the set of input data, element by element. Meaning, in the first step they choose one of the values that they want to put in order and they do something with it. As we shall see later, this is not the most efficient approach, but it is the simplest.
Let’s start with minsort — its name comes from “minimum sort”. The concept is to go along and at each step take the minimum element of the set (the smallest element) and include it in the already ordered list. Because each time there will only be “larger” elements in the set, this ensures us that at the end of the process we will have an ordered sequence.
Let’s look at an example with the following elements: “ 3, 2, 4, 1, 5.” Minsort will execute five steps in order to get to an ordered list:
- It will look for the minimum element (in this case it’s 1) and will position it as the first ordered value. The remaining elements are “3, 2, 4, 5.”
- It will now look for the new minimum element (which is the 2) and it will place it at the end of our list, which will now be “1, 2.” The remaining elements are “3, 4, 5.”
- The new minimum element is 3, the ordered list is “1, 2, 3” with 4 and 5 remaining.
- In the next to last step, 4 is positioned at the end of the ordered list, “1, 2, 3, 4.”
- The last remaining number is 5, which will close our list, “1, 2, 3, 4, 5.”
A significant point to note is that although after step 2 the set of numbers to be sorted was, in reality, already in sequence, the algorithm is not “aware” of this fact (and we wouldn’t be either if the set were comprised of 1,000 elements instead of 5).
The number of steps in minsort always equals the number of elements to be ordered
Within the same family of algorithms, we find insertion sort. In this case we are also going to increment an already ordered list, but instead of choosing the smallest element each time, we are going to choose the correct position of each element under consideration. For example, if we have the list “a, c” and we want to insert the letter “b,” we will be sure that the output is the list: “a, b, c.” Let’s look at our “3, 2, 4, 1, 5” example and order it using the insertion sort:
- The first element to be addressed is the 3 and it becomes the first element in our ordered list.
- Then we take the 2, which we have to insert in our list with the 3. The algorithm knows that 2 comes before 3, so the resulting ordered list is “2, 3.”
- Now it’s number 4’s turn. The algorithm passes over the first position because 4 is greater than 2, and also the next position since 4 is greater than 3. The result is a new list: “2, 3, 4.”
We continue as such with all the elements until the list ends up being “1, 2, 3, 4, 5” as we would expect.
An important algorithm property, regardless of its ultimate function, is how many steps it has to take to finish running. This is what we call the algorithm’s complexity, and it is one of computing’s fundamental concentrations of study. In the minsort example, at each step we had to look for the smallest element; this entails as many comparisons between elements as elements remaining. Therefore, our example requires 5+4+3+2+1=15 steps. Generally, if we have n elements to arrange in order, we will need to take n*(n+1)/2 steps — and you can confirm that if n is 5, the result is, as given,15). Calculating the complexity of the insertion sort is more complicated because it will depend on how much of the already ordered list we will have to get through before we find the correct position. However, the average result is the same as minsort.
We can do better: we can find algorithms that more efficiently sort data elements.This isn’t a trivial matter: the less time it takes to sort the elements means the less time that users have to wait. Less time also means less energy consumption: more time to enjoy the smartphone on the train commuting to work and less emissions.
Divide and Conquer
The problem with the previously mentioned algorithms is that they are trying to approach their task at a global level, meaning tackling each and every element of the full list separately but in one go. Our next batch of algorithms have been designed to divide the initial set of elements into various subsets, which will be tackled separately. Hence when talking about algorithms we say “divide and conquer,” in reference to the ancient Roman maxim.
Let’s begin with merge sort where “merge” has a technical undertone and refers to a specific way of joining things (elements). But let’s not get ahead of ourselves. Merge sort operates in two phases: first it divides the initial set into halves, then it divides these halves into halves, and so on until it ends up with sets that contain only one element.
In our example, we’ll divide “3, 2, 4, 1, 5” into “3, 2, 4” and “1, 5” (it is inevitable that one of the sets will be larger than the other when we are dealing with an uneven number of elements). Then “3, 2, 4” is divided into “3, 2” and “4”and “1, 5” is divided into sets of a single element. Finally, “3, 2” is also divided in order to reach the goal of having sets of only one element. We can visualize this process like a tree (or at least like what computer scientists understand by “tree”):
Tree 1
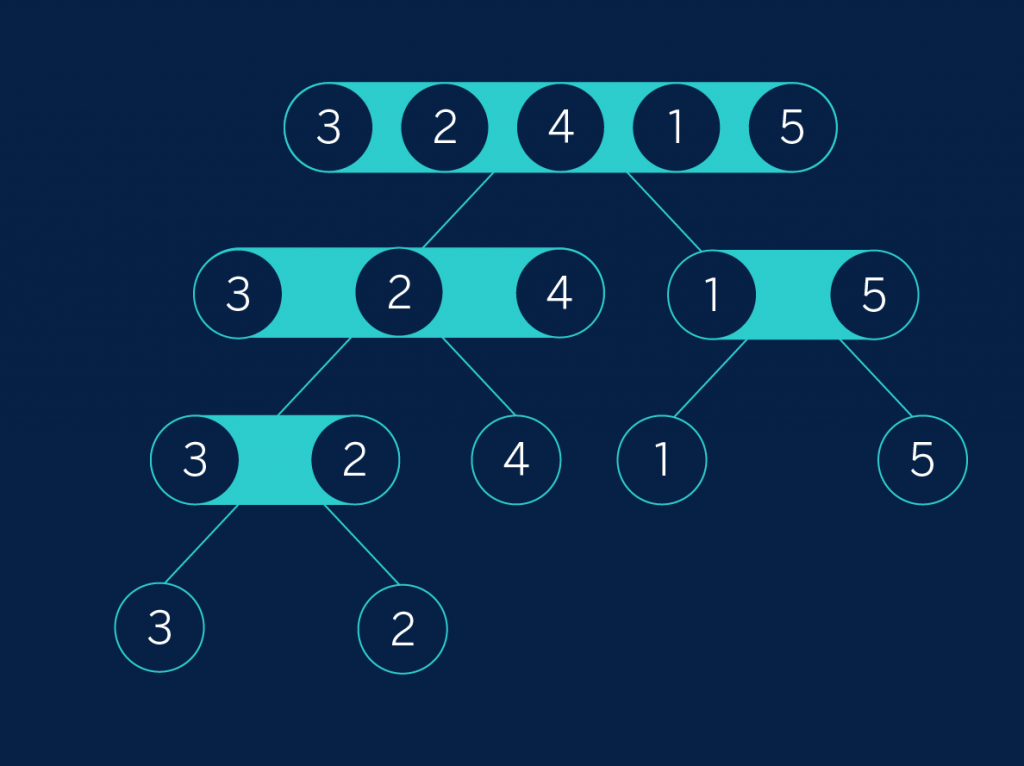
The second phase of merge sort consists in rebuilding the list, but ensuring that at each step it is ordered. The first thing we must appreciate is that a list containing only one element will always be ordered. Secondly, if we have two already ordered lists, we can easily join them by examining them in parallel and choosing the smaller element of the two lists each time. This procedure is what we technically call “merging” a pair of ordered lists.
In our example, we begin with the two lists “3” and “2.” Merging them results in the list “2, 3.” We have already looked at all the lists at this level, so we’ll go up a level on the tree. First we have the list “2, 3″ (the ordered version of “3, 2” and “4”, merging them results in the ordered list “2, 3, 4.” On the other side of the tree, we get the list “1, 5.” Finally, we have to merge “2, 3, 4” and “1, 5.” This whole process can be viewed as the inverse of the separation phase:
Tree 2
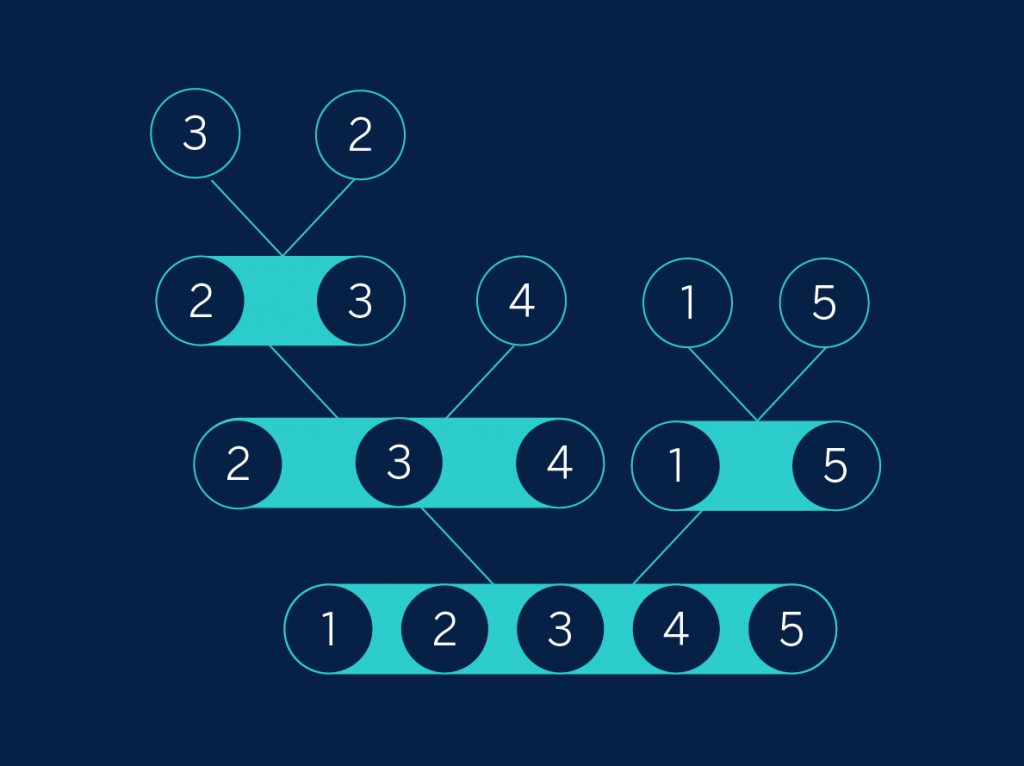
The appeal of all this is that the subsets to be ordered are becoming exponentially smaller: with each step we divide the set by half. Mathematically, we see that the number of “levels” in our tree is the logarithm of the initial number of elements to the base of 2. As a reminder of our math lessons in times of yore, the logarithm of n to the base of 2 will be the exponent to which 2 is raised in order to get the original n. For example, the logarithm of 8 to the base of 2 is 3 because 2 to the power of 3 equals 8. At each level we have to merge as many elements as we had at the beginning, so ultimately we determine that the complexity of merge sort is n*log_2n. The specific number isn’t as important as the fact that it is less than the two previously discussed algorithms.
The way to divide elements in merge sort is quite easy: half for each side. But there is another way to approach the problem, which is used by the quick sort algorithm. What we do is choose any element from our list to be a separator, also known as the pivot, (the choice of pivot ultimately isn’t important). We will separate those elements that are smaller than the separator from those that are larger.
In our example, “3, 2, 4, 1, 5”, we will choose the central element as the separator. In this first step, the central element is the 4, so we divide the elements between those that are smaller (3, 2, 1) and those that are greater (5). Now we do the same thing with “3, 2, 1”: we will take 2 as the central element and we separate the smaller (1) and the greater (3). We can see this process in a tree:
Tree 3
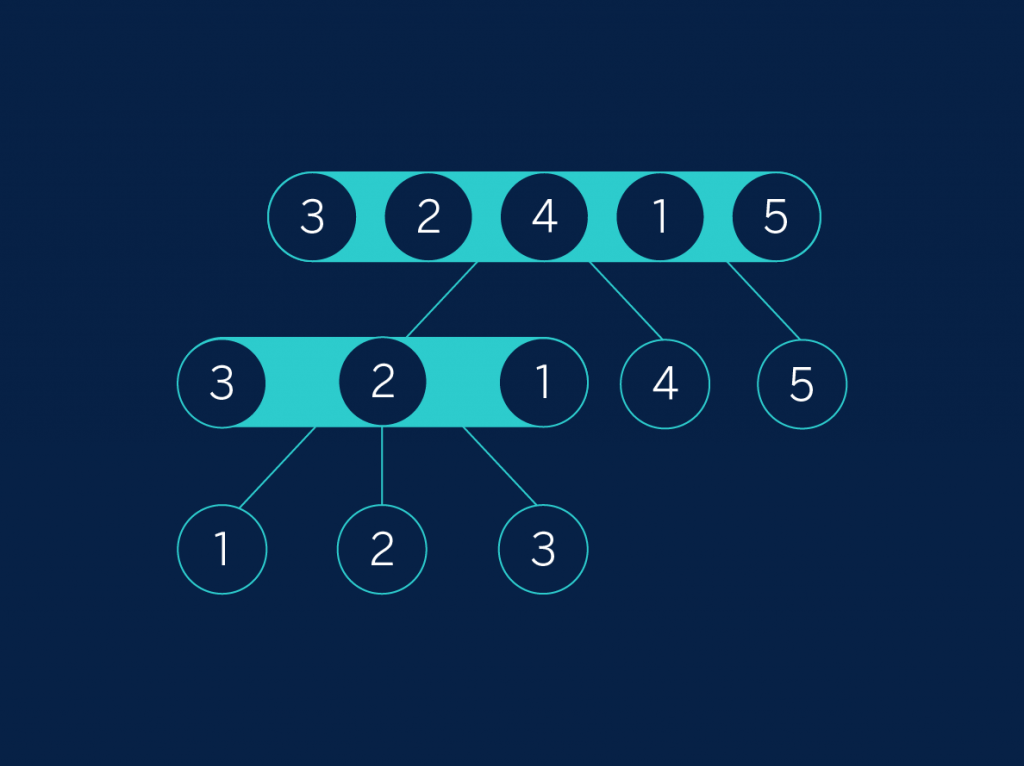
The appeal of this approach is that now we don’t need a second pass at merging: if we read the elements from the lowest branch of the tree up, we immediately get the ordered list! The only difficulty with this approach is that in addition to the division, we also have to remember what we have used as the pivot.
Performing a slightly more complex calculation than we did for merge sort, for the quicksort we get a similar level of complexity. So, where does the “quick” in the name come from? It turns out that if we factor in other variables of the algorithm, such as memory usage and data backup transfers, quicksort ends up being a much better option in practice than merge sort. Nevertheless, this analysis is only valid if we run the algorithm sequentially; if we can divide the work between various parallel processors, merge sort proves itself to be a worthy contender. At any rate, when speaking about ordering or sorting data, most programmers end up using quicksort or some variation thereof.
Organizing into piles
Let us now imagine the following: we give you a pile of passports and ask you to sort them by number (and we assume that the passport is really a number, not a jumble of letters and digits). What would you do?
Surely nothing like what we’ve described thus far. No: you would start by making a pile with all the passports that begin with 1, another of those starting with 2, and so on (and if you are like me, you would realize at the end that you also need a pile for those starting with 0). Then you would take the number 1 pile and you would repeat the process with the second number until you end up with piles of only one passport (or having small piles that you can arrange by simple eyeballing.) Congratulations, you’ve executed an algorithm without knowing it: radix sort (also known as “bucket sort”).

Without having conducted a comparative study, it seems as if this is the most “natural” way for humans to sort. This algorithm, however, is not frequently used in programming. The reason is because we “see” the number as a series of digits, 41 is naturally a 4 then a 1. For a computer, a number is a total entity and indivisible: if we want to replicate our passport ordering exercise using a computer, it would take us a good bit of work to get “the first digit of the number.” Apart from all this, it is easy for us to make 10 piles because we have fully assimilated the sequence of digits. Computers, though, see numbers composed of 1s and 0s, so for them it would “make more sense” to make 2 piles. So, we return to the merge or quicksort approaches.
Is there a better approach?
Computer science relies significantly on mathematics. Specifically, as opposed to physics or chemistry, in information technology we can test specific theorems in any situation, not just hypotheses to be validated in nature. One such theorem tells us that we cannot substantially improve upon the time it takes us to sort things using merge or quicksort.
But watch out! This theorem is only true for our initial problem. If we can assume that part of our set is already ordered, such as the case of inserting an element in a database, we can do better. Furthermore, all of this discussion has assumed we are working with a conventional computer, only able to perform a single operation at a time. This barrier may just fade away once quantum computing hits the mainstream.
Comments on this publication