In the previous article we introduced the idea of high-level language and the role of the compiler as a translator between those languages and the machine language, which is what the processor understands. Thinking at a high level means avoiding having to think even in the smallest detail of our program, using abstractions as variables or functions, closer to the human way of thinking. But as we will see in this article, on top of these basic abstractions there are many others, and different languages provide different subsets of them.
Programming languages are a purely human creation that, in a sense, reflect the mindset of their creators. It is therefore no surprise that there are hundreds (if not thousands) of languages, grouped into about ten different families, according to the different ways programs are structured. Thinking of a program in a linear way is not the same as thinking of it as a response to a series of outside events. The language used in the first type is preferable for tasks with a clear beginning and end, such as working out tomorrow’s weather. The second abstraction is more useful for describing the workings behind a mobile application in which you can touch various elements on the screen.
Funnily enough, discussions on programming languages would suggest that many of the differences between the two are purely esthetic. For example, to express “variable x has a value of 5,” is it best to write “x = 5” (as we do in Java or in C), “x := 5” (as we do in Pascal) or “x < – 5” (as we do in R)? These discussions are so heated that famous language designer Philip Wadler proposed a law that said that exponentially more time was spent discussing language syntax (the way in which concepts are translated into symbols) than semantics (the ideas behind what we write).

Let’s go back to discussing the different abstractions each language family offers us. Although they can be classified in various different ways and in as much detail as we like, there are four main commonly accepted families or paradigms: imperative programming, object-oriented programming, functional languages and logic programming. The latter two usually come under the single heading of declarative programming.
Imperative and object-oriented languages
A program written in an imperative programming language is essentially a sequence of commands or orders (this is where it gets its name from) that are executed from start to finish. The most basic commands are to modify the value of a variable or call a function; i.e. the simplest abstractions we talked about in our last entry. Imperative programming languages add the following two elements to these basic orders:
- Conditional statements: a way of redirecting the flow of the execution depending on a value or property. Example: if the name text box is empty (condition), display an error message (order).
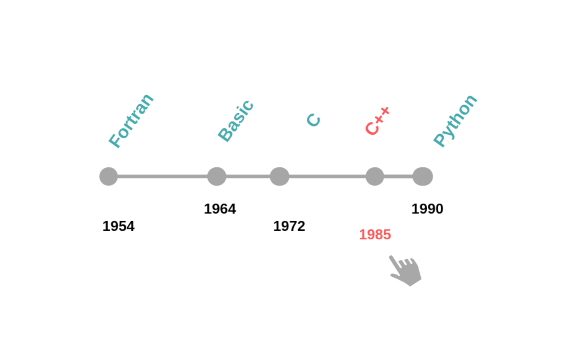
- Loops: a way of repeating a series of orders. Example: for every number from 1 to 10, display this number on the screen. We don’t need to know the number of repetitions beforehand. This can depend on another condition. For example, display the message “press Y or N” on the screen until the user presses Y or N. Given the simplicity of these abstractions, many languages in other families also provide them. As pure imperative programming languages, we can highlight Fortran (born in 1954), Basic (1964), Pascal (1970), C (1972), and Python (1990). One of the main advantages is that these abstractions are very close or easy to translate to machine language. This is why a large proportion of high-performance software continues to be written in this paradigm.
However, as programs have grown in size and complexity, there has been a need for new abstractions which put even more distance between the programmer and the virtual machine. The first ideas of object-oriented programming were introduced in the mid-1960s. By 1970, there were already programming languages, such as Simula or Smalltalk, made using solely this paradigm. However, it exploded in 1985 with the arrival of C++, becoming the leading paradigm. Almost every new “mainstream” language since then — such as Java, Ruby or C# — has been object-oriented.
The fundamental idea of this paradigm is that the code is articulated through many different objects (sometimes called actors) that work independently and communicate with each other. If we want to print a restaurant check, we will communicate with a “check object,” which we will tell what has been ordered. This object will independently calculate the total and communicate with another “printer object” to print the check. The greatest advantage of this paradigm is its modularity: different teams can work independently on different parts of a program, and they only need to agree on how these objects or actors will communicate with each other.
Most object-oriented languages introduce the concept of subtyping to this common idea. Subtyping is a way of taking a step back from the peculiarities of each object. The most commonly used example is that of animals: sometimes I need to communicate with a “dog object” or a “cat object”, but sometimes a “pet object” is enough. In object-orientated programming, we can say that a dog is a pet and we can use the first instead of the second, without any problem. For a more IT-related example: the “printer object” mentioned earlier could be a subtype of an “information-sending object” of which another subtype could be “email-sending object” that sends the check by email.
Declarative Programming Languajes
Giving orders to the computer is the opposite of trying to explain to the computer what you want to do and letting it find a way to give you the result. That is, at least, the philosophy behind declarative languages: to provide a high level of language where the programmer expresses the problem in itself, and not so much how the program runs. Traditionally, the disadvantage of these languages has been the speed — translating everything into a series of simple commands is a difficult task for the compiler. However this has been reduced considerably in recent decades.
Logic programming languages look at the world as a series of “facts” that are taken as true and a series of “rules” for inferring information from those facts. A clearer example is the following description of family relationships between fathers and sons:
> Alex is Julian’s son.
> Quique is Alex’ son.
> Julio is Alex’s son.
Together with a rule that says “Mr. X is the grandfather of Mr. Y” if “Mr. Y is the son of Pepito AND Pepito is the son of Mr. X.” In a logic language we can now ask closed questions such as, “Is Julio Quique’s grandfather?” — to which it would answer “no.” Or we can ask open questions such as, “Is Julian the grandfather of grandson?” — to which it would answer “grandson = Quique, grandson = Julio,” because those are the two values of “grandson” which have an affirmative answer.
These languages were very popular in the first waves of artificial intelligence, as they were considered to be a good representation of information and its rules. Prolog, born in 1972, is practically the only survivor of this paradigm in its pure state to this day and continues to be the object of study. At present, when there is a need for a system of rules like the one provided by logic programming, it is usually integrated as part of a program written in another paradigm.
Functional Languages
The other main family in declarative programming is made up of functional languages. Earlier, we said that one of the abstractions par excellence is to give a name to a value in a program. In most languages, when we say “value” we mean a piece of data, such as a number, a person’s information, and so on. In a functional language, the barrier between variable and function is blurred, and we can manipulate a function (i.e., a sequence of instructions for the computer) like any other value. For example, let’s imagine that we have a list of people and want to perform an operation for each one of them. In an imperative language, we have to write a new loop for every operation that we want to perform. In functional programming we have an operation that receives another function and executes it on each item on the list. This prevents us from having to write a loop every time.
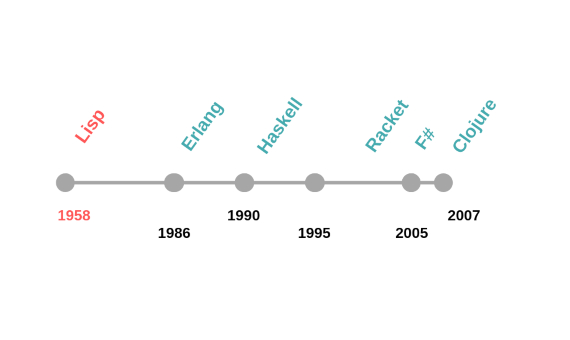
Functional programming dates back almost as far as computers themselves. It derives from a computer model called lambda calculus, invented in the 1930s by Alonzo Church. Lisp, the second high-level programming language in history (1958), is a functional language. More recent examples include Erlang (1986), Haskell (1990), Racket (1995), F# (2005) and Clojure (2007). Furthermore, there is a tendency to incorporate elements of functional programming into pre-existing languages, such as Java, or to mix object-oriented and functional programming, such as Scala (2004) or Swift (2014).
Domain-specific languages
All of the languages we have discussed so far are general-purpose. This means that, generally speaking, these languages allow us to express any computational need we may have. There are other languages that focus on solving problems in a particular area (or domain), deliberately excluding other uses. For example, the web page you’re reading right now is written in a language called HTML, focused only on rendering text and images with possible links to other web pages (it is likely that if you right-click there will be a “view code” option that shows you the HTML).
An important need for information systems is to consult and modify databases. Here we find another domain-specific language (SQL), aimed at expressing those queries in the most concise way possible. Finally, a well-known example is spreadsheets. Each time we write a formula in a cell, such as “=SUM(A1:A20),” we are writing in a language of mathematical formulas.
From the outside, it may seem that “writing a program” is something that is done in a specific way. But, as we have seen, in half a century of computer science, a multitude of programming languages have been created, providing a wide variety approaches for problems that need solving.
Alejandro Serrano Mena
Comments on this publication