Hasta ahora, el ritmo de adopción de métodos de inteligencia artificial y aprendizaje automático (AI/ML) ha sido bastante desigual en el área de las ciencias económicas, concentrándose en gran medida en el ámbito de la microeconomía, donde el incremento exponencial en la recopilación de datos, especialmente a nivel de consumidores individuales (empresas como Amazon), han evidenciado las principales ventajas de la dupla AI/ML, dado que, para ser útiles, estos modelos requieren grandes volúmenes de datos.
Pero, ¿qué posibilidades existen para la aplicación de herramientas de inteligencia artificial en el ámbito de la macroeconomía, la rama de la economía que pone el foco sobre la economía a gran escala, centrándose en regiones enteras, países o incluso el mundo? ¿Cuáles son las diferencias entre las herramientas estadísticas tradicionales que utilizan los macroeconomistas y los modelos que combinan inteligencia artificial y aprendizaje automático?¿Se trata de una exageración o de una realidad, especialmente dado que la macroeconomía no se presta a producir datos a la misma escala que la microeconomía? Al fin y al cabo, en el mundo no coexisten millones de países, mientras que Amazon cuenta con millones de consumidores

Este ejercicio de reflexión es el primero de una serie de tres en los que iré desgranando mis conjeturas (sean economistas o no) para guiar a sus lectores en la búsqueda de respuestas a algunas de estas preguntas. En este primer ensayo expondré la que considero que es, partiendo de mi propia experiencia como economista corporativo en los sectores público y privado y de trabajos de terceros, la principal diferencia entre las proyecciones derivadas de la macroeconomía clásica y las que se han podido generar hasta la fecha utilizando herramientas de inteligencia artificial y aprendizaje automático.
CÓMO FUNCIONA LA ECONOMETRÍA TRADICIONAL: UN EJEMPLO DE LA MACROECONOMÍA
Para este primer ensayo, analizaremos un problema del mundo real que puede planteársele a un macroeconomista tipo y compararemos un enfoque econométrico convencional con una solución general basada en el aprendizaje automático.
Todos tenemos una idea aproximada sobre qué factores hacen crecer nuestras economías locales o nacionales. Las distintas ideas sobre las palancas del crecimiento económico son clave en procesos electorales, pero su influencia va mucho más allá. Por ejemplo, ¿a qué se debe que la tasa media de incremento del PIB de EE.UU. fuera del 2,3% entre 1950 y 1973, para estancarse muy por debajo del 2,0% a partir de entonces? ¿O que China haya crecido casi un 10% anual de media durante los últimos 40 años? O, por otro lado, ¿cuál va a ser la tasa de crecimiento de la economía el año que viene o incluso durante los próximos tres meses para informar a la cúpula directiva o a la junta de accionistas de una empresa?
Siendo una ciencia social, los macroeconomistas han desarrollado numerosas teorías y modelos para explicar y pronosticar el crecimiento económico. Y a todos se nos ocurren múltiples factores que contribuyen al crecimiento económico. Cosas como el nivel de gasto del gobierno o de los consumidores, que dependen en gran medida de cosas como los tipos de interés o incluso otras más difíciles de medir, como la confianza de los mercados y de mercado y de los consumidores. Pero también sabemos que existen muchos otros factores que también influyen, como son la inflación, las dinámicas comerciales (incluido el tipo de cambio), el precio de las importaciones (como el petróleo) e infinidad de diferentes tipos de políticas que impactan sobre todo lo anterior, entre muchos otros. En una revisión de la literatura, Durlauf, Johnson, Temple (2005) identificaron hasta 145 variables que habían sido utilizadas en regresiones de crecimiento objeto de diferentes estudios.

Este volumen de variables explicativas se deriva de los cientos de teorías que se han postulado para explicar el crecimiento económico. En econometría aplicada, uno de los ejercicios más frecuentes es evaluar el impacto de las variaciones de una co-variable manteniendo las demás constantes. Y este deseo de explicar, tanto para contribuir al desarrollo de teorías económicas como para orientar a los responsables de la formulación de políticas, es el objetivo principal de los enfoques econométricos tradicionales.
DIFERENCIAS ENTRE MODELOS ECONOMÉTRICOS CON HERRAMIENTAS DE INTELIGENCIA ARTIFICIAL/APRENDIZAJE AUTOMÁTICO – OTRA MIRADA AL MISMO EJEMPLO DE LA MACROECONOMÍA
Los modelos que incorporan herramientas de inteligencia artificial/aprendizaje automático, por otro lado, priorizan la predicción por encima de la explicación, puesto que están mucho mejor equipados para abordar este tipo de tareas. En su mayor parte, las predicciones elaboradas a partir de modelos econométricos tradicionales no suelen ser demasiado buenas. En concreto, los modelos basados en el método de mínimos cuadrados ordinarios (MCO) tienen dificultades para hacer buenos pronósticos cuando (1) se dispone de multitud de variables predictoras (o más bien muchas variables predictoras en relación al número de observaciones); (2) muchas de las variables predictoras están correlacionadas entre sí (colinealidad); (3) muchas de las variables predictoras son irrelevantes; o (4) la forma en que los datos se generan en la naturaleza no es lineal. Retomando el ejemplo que hemos visto antes de modelado de crecimiento del PIB, ¿a qué nos suena esto?
Por el contrario, los modelos que combinan métodos AI/ML son máquinas de predecir. Como Mullainathan et al. (2017) resumen, el éxito de las herramientas de inteligencia artificial/aprendizaje automático es que permiten “descubrir estructuras complejas que no se han especificado de antemano”. En primer lugar, los modelos AI/ML generalmente no tienen problemas para manejar relaciones complejas, no lineales entre grandes (enormes) volúmenes de variables predictoras. Ello se debe a que estos modelos permiten gestionar mucho mejor la compensación entre sesgo y varianza, gracias a los llamados procedimientos de regularización y validación cruzada. Esta frase está repleta de expresiones que están de moda. Veamos primero qué se entiende por sesgo y varianza, porque es muy importante.
Para ello, retomaremos el modelo de crecimiento económico que hemos comentado anteriormente. Supongamos que queremos reducir la complejidad de nuestro modelo de una manera efectiva y utilizar una única variable predictora; en ese caso podríamos predecir el crecimiento del PIB del año usando únicamente el del año anterior. Un modelo tan sencillo como este, por supuesto, nunca será demasiado bueno para hacer predicciones y sus pronósticos estarán plagados de errores. Estos errores se deben a sesgos, puesto que el modelo parte de la suposición incorrecta de que el crecimiento económico futuro solo depende de la tasa de crecimiento del año (o trimestre, mes, etc.) anterior. El siguiente gráfico que propone Hall (2018) ilustra muy bien cómo funciona esto.
Figura 1. Errores de pronóstico debido a sesgo y varianza
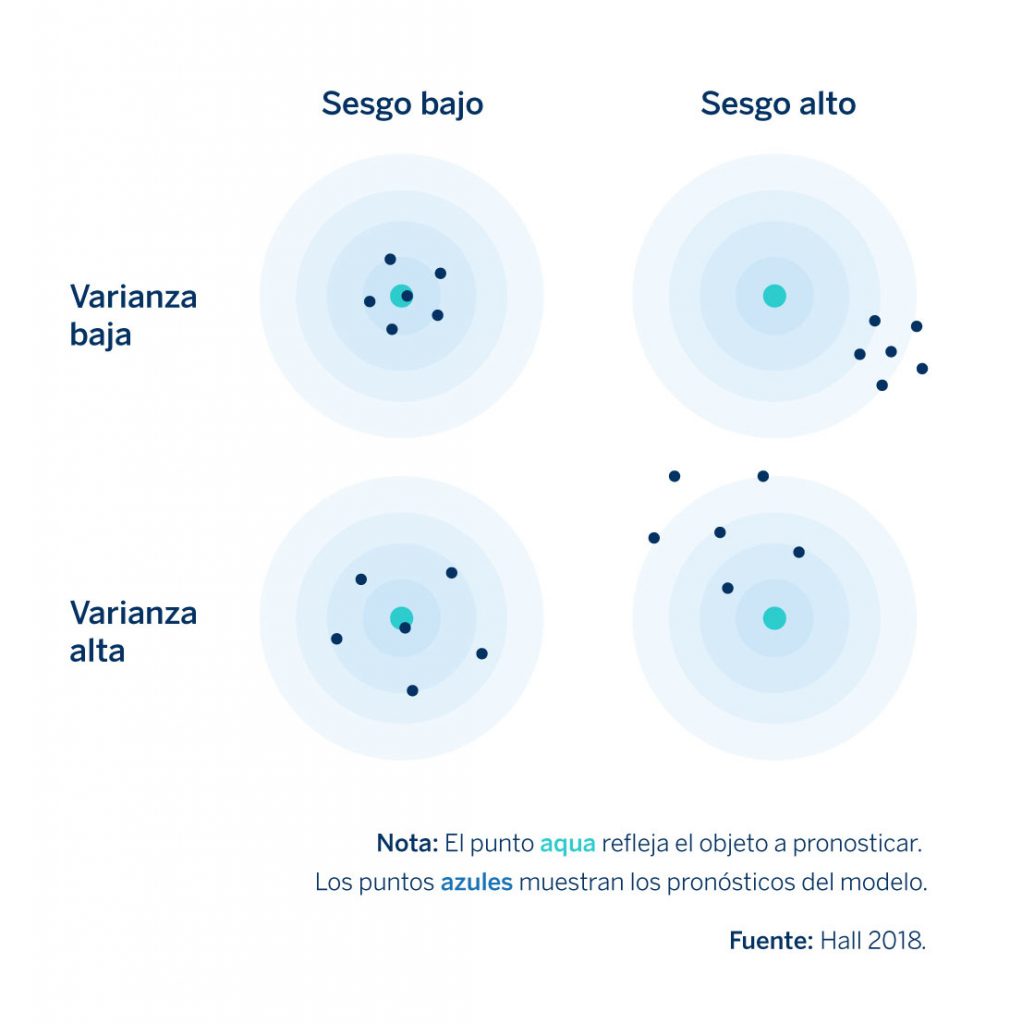 El punto aqua en el centro representa la predicción correcta, mientras que los puntos azules muestran las predicciones del modelo para cuatro situaciones diferentes: combinaciones de varianza alta o baja y sesgo alto o bajo. Un modelo simple, como el que acabamos de ver, tendrá errores de pronóstico como los del cuadrante superior derecho del gráfico (alto sesgo- varianza baja en la Figura 1) debido a que, en general, los modelos simples exhiben de niveles elevados de sesgo porque no captan los matices de los factores que favorecen el crecimiento económico (en este caso) muy bien. Sin embargo, a cambio de este sesgo, los pronósticos de este tipo de modelo suelen tener una varianza menor, lo cual implica que son más robustos al ruido presente en los datos. Al fin y al cabo, ¿cuánto ruido va a existir en un modelo con una única variable predictora frente a uno con, por ejemplo, 30? Las predicciones generadas a partir de modelos con errores de sesgo no suelen ajustarse suficientemente a los datos. Las predicciones de un modelo así serán tan deficientes como estables en el tiempo.
El punto aqua en el centro representa la predicción correcta, mientras que los puntos azules muestran las predicciones del modelo para cuatro situaciones diferentes: combinaciones de varianza alta o baja y sesgo alto o bajo. Un modelo simple, como el que acabamos de ver, tendrá errores de pronóstico como los del cuadrante superior derecho del gráfico (alto sesgo- varianza baja en la Figura 1) debido a que, en general, los modelos simples exhiben de niveles elevados de sesgo porque no captan los matices de los factores que favorecen el crecimiento económico (en este caso) muy bien. Sin embargo, a cambio de este sesgo, los pronósticos de este tipo de modelo suelen tener una varianza menor, lo cual implica que son más robustos al ruido presente en los datos. Al fin y al cabo, ¿cuánto ruido va a existir en un modelo con una única variable predictora frente a uno con, por ejemplo, 30? Las predicciones generadas a partir de modelos con errores de sesgo no suelen ajustarse suficientemente a los datos. Las predicciones de un modelo así serán tan deficientes como estables en el tiempo.
En la otra cara de la moneda tenemos los modelos con errores derivados de la varianza. En lugar de un modelo con solo una variable predictora, imaginemos uno con 50 variables predictoras, configuradas para explicar, digamos, una serie temporal de crecimiento anual del PIB que solo puede abarcar unos 40 años. Es probable que este modelo refleje mejor qué condiciones contribuyen al crecimiento económico frente a nuestro modelo de predicción porque es más complejo o “realista”. Sin embargo, existen muchas posibilidades de que este modelo pueda “sobreajustarse”, porque parte de un gran conjunto específico de variables que han sido útiles para explicar el crecimiento del PIB pasado, pero que quizás no sea lo suficientemente general para explicar el crecimiento a futuro (sesgo bajo – varianza alta en la Figura 1). Dado el gran volumen de variables, es muy probable que los cambios, o el ruido que afecte a las mismas en un futuro, se traduzcan en una capacidad de pronóstico deficiente.
La relación entre sesgo y varianza en el pronóstico puede considerarse como una relación de compensación, porque normalmente es imposible reducir ambos simultáneamente (Bolbuis y Rayner 2020. James et al. 2013), y los modelos que incorporan AI/ML están diseñados para gestionar esta compensación de una manera más efectiva. Para ello se aplican dos procesos, que son mucho más utilizados en los modelos IA/ML que en la econometría tradicional. En mi siguiente post veremos con más detenimiento estos dos procesos en el contexto de modelos de IA/ML más específicos, pero a modo de resumen, se trataría de:
- La validación cruzada, que es el proceso de buscar mejores predictores dividiendo el conjunto de datos en múltiples subgrupos (‘pliegues’) y entrenando el modelo en algunos de estos subgrupos (‘pliegue de entrenamiento’) antes de evaluarlo en otros (‘pliegue de prueba’). Así pues, si tuviéramos datos de crecimiento del PIB durante 20 años, podríamos dividir ese período en diferentes pliegues (diferentes combinaciones de años) y aplicar el modelo (o varios modelos) y luego probar el modelo sobre los períodos de tiempo que no han sido incluidos en la prueba. Esto contrasta con gran parte de la econometría, donde los modelos se ejecutan sobre toda la serie de datos. El enfoque tradicional ofrece algunas ventajas para probar teorías causales, pero no es tan útil para efectuar predicciones, ya que tiende a “sobre ajustarse” al modelo.
- El método de regularización permite al modelador construir un modelo relativamente complejo, reduciendo la posibilidad de sobreajuste para efectuar pronósticos acertados. De entre la multitud de métodos de regularización existentes, como veremos en mi próxima publicación, existe uno que penaliza a aquellos que sobre ajustan los datos. Esta penalización puede consistir en limitar el número de variables en un modelo o la medida en que cualquier variable determinada contribuye a los pronósticos del modelo (es decir, la magnitud de los coeficientes del modelo). Además de reducir los riesgos de sobreajuste, la regularización ofrece una aportación prometedora adicional: al reducir la contribución de predictores menos importantes, este planteamiento puede ayudar a los investigadores a descubrir relaciones en los datos que no habían considerado previamente. Por lo tanto, en teoría, la regularización podría ayudar a desarrollar teorías en economía, aunque no tengo constancia de ningún ejemplo importante en el que esto haya ocurrido.
CONCLUSIÓN:¿COMPARANDO MANZANAS Y PERAS?
Hemos analizado las ventajas y desventajas de los modelos que combinan herramientas de inteligencia artificial y aprendizaje automático frente a los planteamientos econométricos tradicionales, pero no por ello debemos necesariamente entender que se trata de dos enfoques mutuamente excluyentes. Para empezar, hay muchas cosas que pueden tomarse prestadas de ambos enfoques para mejorarlos. Por ejemplo, la validación cruzada podría convertirse en una metodología estándar de aplicación en todo el ámbito de la economía empírica en el futuro (Athey e Imbens. 2019). Además, en lugar de excluirse, existen argumentos para considerar que los dos enfoques pueden ser complementarios. Los modelos AI/ML no son eficaces para desarrollar teorías (a día de hoy), pero permiten realizar mejores pronósticos. Además, permiten analizar datos de alta dimensión, algo que es básicamente imposible con enfoques tradicionales. Con este fin, en nuestra próxima publicación veremos cómo los enfoques AI/ML pueden arrojar luz sobre problemas macroeconómicos aprovechando imágenes de satélite, fotografías y texto.
Bryce Quillin
Fuentes
Athey, Susan and Guido W. Imbens. 2019. Machine Learning Methods Economists Should Know About. March.
Bolbuis, Marijn A. and Brett Rayner. 2020. Deus ex Machina? A Framework for Macro Forecasting with Machine Learning. IMF Working Paper. WP/20/45.
Hall, Aaron Smalter. 2018. Machine Learning Approaches to Macroeconomic Forecasting. Economic Review. Federal Reserve Bank of Kansas City.
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2013. An Introduction to Statistical Learning with Applications in R. New York: Springer.
Mullainathan, Sendhil and Jann Spiess. 2017. Machine Learning: An Applied Econometric Approach. Journal of Economic Perspectives. Vol 31, Number 2. pps. 87-106
Comentarios sobre esta publicación