So far, the adoption rate of methods of artificial intelligence and machine learning (AI/ML) has been quite uneven across the economics profession. The uptake of these methods has been heavily concentrated in microeconomics where an explosion of data collection, particularly at the level of individual consumers (think of a firm like Amazon) has made the benefits of AI/ML especially clear and possible given that these models require massive amounts of data to be useful.
Yet what are the prospects for applying the tools of AI to macroeconomics – that branch of economics that looks at the performance of big things like whole regions, countries, or even the globe? What are the differences between traditional statistical tools that macroeconomists use and AI/ML-based approaches? Is it more hype than reality, particularly given that macroeconomics does not lend itself to producing data at the same scale as microeconomics – after all, the world does not have millions of countries in the same way that Amazon has millions of consumers

This thought piece is the first of three that will walk readers (whether economists or not) through my guesses at answering some of these questions. This first essay will lay out what I see, guided by my own experience as a corporate economist in the public and private sectors as well as the writing of others, as the key difference between traditional macroeconomic forecasting and what has been delivered so far by AI/ML-type approaches.
How does traditional econometrics work – an example from macroeconomics
For this first essay, let’s consider a real-world problem that one type of macroeconomist may encounter and compare a conventional econometric approach to a general machine learning-based solution.
All of us have some ideas of what sorts of things cause our local or national economies to grow. Different ideas about the drivers of economic growth influence whole elections and, in some cases, significantly more. For example, what explains why the average GDP growth rate of the U.S. was 2.3% during 1950-73 but then slowed to an average of well below 2.0% afterward? Or why has China grown by almost 10% a year on average for the past 40 years? Or on the high-frequency side, what will economic growth be next year or even over just the next three months to report to your C-suite management or at the shareholders’ meeting?
Being a social science, macroeconomists have developed numerous theories and models to explain and forecast economic growth. And we can all think of lots of things that drive economic growth. Things like how much the government or consumers spend, both of which have a lot to do with interest rates or harder to measure things like positive or negative market and consumer sentiment. But we also know that innumerable other things matter like inflation, trade dynamics (including exchange rates), the price of imported goods (like oil), and an endless array of different types of policies that impact all of the above and many more. The literature review of Durlauf, Johnson, Temple (2005) found as many as 145 different variables included in growth regressions in published papers!

The number of explanatory variables is so large because hundreds of theories have been developed to explain economic growth. In applied econometrics, the key objective is often to perform exercises like evaluating the impact of changing one covariate while holding others constant. And this desire to explain — both to drive theory-building in economics and guide policy-makers — is the main objective of traditional econometric approaches.
How does an AI/ML approach to econometrics differ – another look at the example from macroeconomics
AI/ML approaches, on the other hand, are far more concerned with prediction than explanation and are better equipped to tackle it. For the most part, traditional econometric models are not that great at forecasting. In particular, models based on the old ordinary least squares (OLS) method struggle to make good forecasts when (1) you have lots of predictor variables (or rather lots of predictor variables relative to the number of observations); (2) lots of the predictor variables are correlated with one another (collinearity); (3) you have lots of irrelevant predictor variables; or (4) the way that the data are generated in nature is non-linear. Based on our example of modeling GDP growth described above, does any of this sound familiar?
By contrast, models based on AI/ML methods are engines of forecasting. As Mullainathan et al. (2017) summarize, the success of AI/ML is, “discovering complex structure that was not specified in advance.” First, AI/ML models generally have no problem handling complex and non-linear relationships between lots (and lots) of predictor variables. The reason for this is that these approaches are much better at managing the trade-off between bias and variance through procedures called regularization and cross-validation. Ok lots of buzz words there. Let’s start first by discussing what is meant by bias and variance as this is super important.
Let’s go back to the economic growth model that we discussed above. Let’s say we wanted to effectively eliminate our model’s complexity and use just a single predictor variable; perhaps we just use the previous year’s GDP growth to predict this year’s growth. A simple model like this will, of course, not be very good at making predictions and will have large forecast errors. These errors originate from bias because it relies on the incorrect assumption that future economic growth is only dependent on the growth rate of the previous year (or quarter, month, etc.). The below graph from Hall (2018) nicely illustrates how this works.
Figure 1. Forecasting Errors due to Bias versus Variance
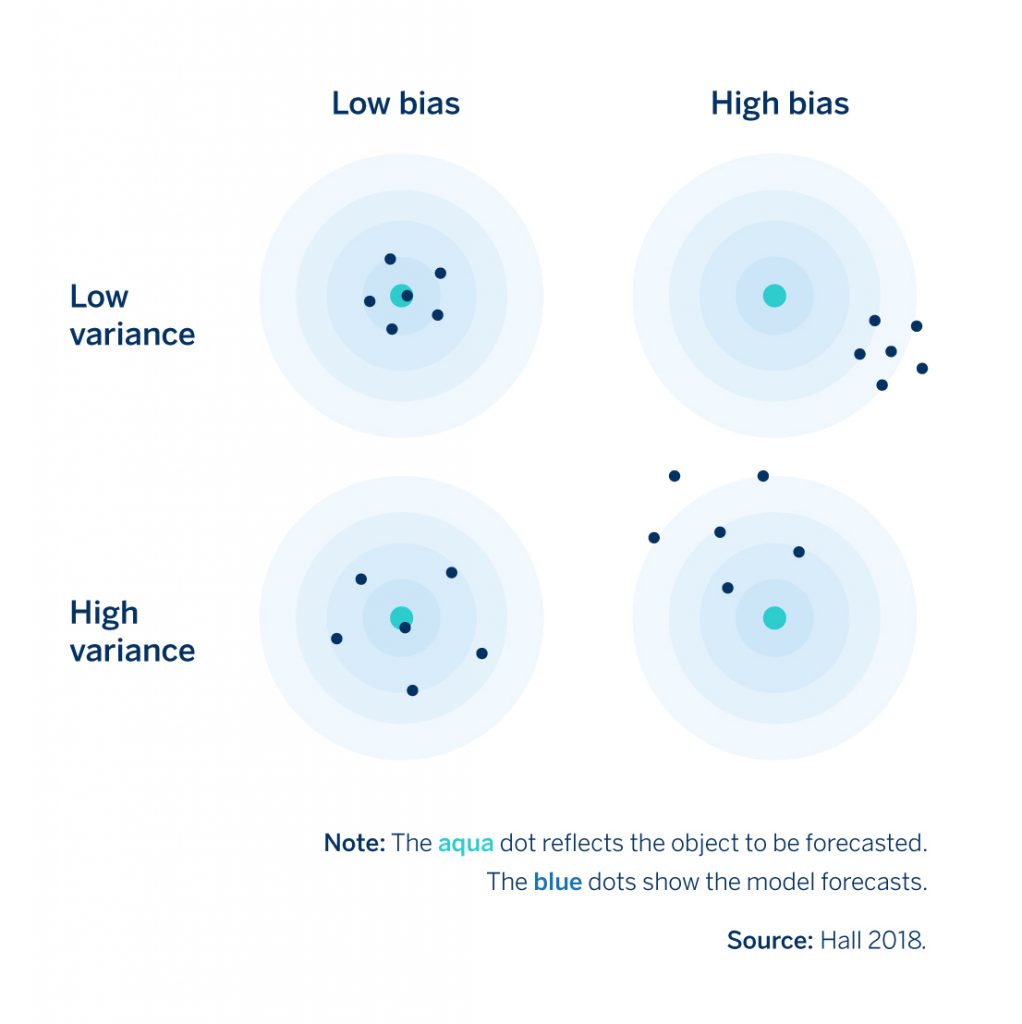 The aqua dot at the center represents the correct prediction while the blue dots show model predictions for four different situations: combinations of high or low variance and high or low bias. A simple model, like that one we’ve just discussed, will have forecast errors like those in the top right of that chart (high bias-low variance in Figure 1) because, in general, simple models exhibit high levels of bias because they do not capture the nuances of what drives economic growth, in this case, very well. Yet, in exchange for this bias the model’s forecasts tend to have lower variance which means that they are more robust to noise in the data. After all, how much noise are you going to have in a model with just one predictor variable as compared to one with say 30? Forecasts produced by models with errors originating from bias often “underfit” the data. Such a model will not forecast very well, but it will be pretty stable over time.
The aqua dot at the center represents the correct prediction while the blue dots show model predictions for four different situations: combinations of high or low variance and high or low bias. A simple model, like that one we’ve just discussed, will have forecast errors like those in the top right of that chart (high bias-low variance in Figure 1) because, in general, simple models exhibit high levels of bias because they do not capture the nuances of what drives economic growth, in this case, very well. Yet, in exchange for this bias the model’s forecasts tend to have lower variance which means that they are more robust to noise in the data. After all, how much noise are you going to have in a model with just one predictor variable as compared to one with say 30? Forecasts produced by models with errors originating from bias often “underfit” the data. Such a model will not forecast very well, but it will be pretty stable over time.
The contrast is models with errors that originate from variance. Instead of a model with just one predictor variable, now imagine a model with 50 predictor variables set up to explain, say, an annual GDP growth time series that may only run for 40 years. This model is likely a better reflection of what drives economic growth as compared with our predictor model because it is more complex or “realistic.” Yet, there is a good chance that this model may “overfit” because it has learned on a very large and specific set of variables which were useful for explaining GDP growth in the past but it may not general enough to explain growth in the future (low bias-high variance in Figure 1). Given the large number of variables, there is a good chance changes or noise in these variables in the future will yield poor forecasting performance.
The relationship between bias and variance in forecasting is best thought of as a trade-off, because it is normally impossible to reduce both simultaneously (Bolbuis and Rayner 2020. James et al. 2013), and AI/ML approaches are built to manage this trade-off more effectively. This trade-off is managed with two processes that are used much more extensively in AI/ML approaches than in traditional econometrics. We will discuss these more in the context of more specific types of AI/ML models in my next post, but briefly, they include:
- Cross-validation is the process of searching for the best predictors by splitting the data set into multiple sub-groups (‘folds’) and training the model on some of these sub-groups (‘training fold’) before evaluating it on others (‘test fold’). So let’s say that you had GDP growth data for 20 years, you could potentially split up that period into different folds (different combinations of years) and apply your model (or various models) and then test on the time periods that you did not include in the test. This contrasts with much of econometrics where the model is run on the entire dataset. The traditional approach has some advantages for testing causal theories but is not as useful for forecasting as the tendency is to “overfit” the model.
- Regularization is a method that allows the modeler to build a relatively complex model while reducing the chance of over-fitting so that it can forecast successfully. There are many methods for doing so that I will discuss in my next post but one directly penalizes a model for overfitting the data. This penalty could be by limiting the number of variables in a model or the extent to which any given variable contributes to the model’s forecasts (i.e., the magnitude of the model’s coefficients). Apart from reducing the risks of overfitting, regularization offers an additional promising contribution: by driving down the contribution of less important predictors, this approach may help researchers discover relationships in the data that they had not previously considered. Theoretically, then, regularization could contribute to theory building in economics though I am unaware of an important case where this has occurred.
Conclusion: Apples to Oranges Comparison?
So far we have discussed the advantages and disadvantages of AI/ML approaches relative to traditional econometric approaches, yet we should not necessarily infer that these approaches must be competitors. For a start, there is much that the two approaches can borrow from one another. For example, cross-validation could become standard in all of empirical economics in the future (Athey and Imbens. 2019). In addition instead of being substitutes, there is an argument that the two approaches can be complements. AI/ML is not an effective tool of theory building (so far), yet is a better tool of forecasting. In addition, AI/ML permits the analysis of high-dimensional data that is basically impossible with traditional approaches. To this end in our next post, we will discuss the way that AI/ML approaches can shed light on macroeconomic problems using satellite imagery, photographs, and text.
Bryce Quillin
Sources
Athey, Susan and Guido W. Imbens. 2019. Machine Learning Methods Economists Should Know About. March.
Bolbuis, Marijn A. and Brett Rayner. 2020. Deus ex Machina? A Framework for Macro Forecasting with Machine Learning. IMF Working Paper. WP/20/45.
Hall, Aaron Smalter. 2018. Machine Learning Approaches to Macroeconomic Forecasting. Economic Review. Federal Reserve Bank of Kansas City.
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2013. An Introduction to Statistical Learning with Applications in R. New York: Springer.
Mullainathan, Sendhil and Jann Spiess. 2017. Machine Learning: An Applied Econometric Approach. Journal of Economic Perspectives. Vol 31, Number 2. pps. 87-106
Comments on this publication