25 years ago, when Tim Berners-Lee presented the WorldWideWeb browser at CERN, he could not have imagined how applications of this type would revolutionize access to information.
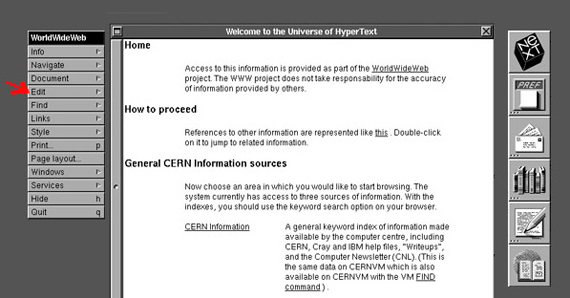
Tim Berners-Lee, the father of the Web, was also the creator of the first browser in history, presented on February 26, 1991 on a NeXT computer, exactly a quarter century ago. It was called WorldWideWeb, but was soon renamed Nexus to avoid confusion between “the program and the abstract information space of the same name,” according to Berners-Lee himself. That humble little program read and wrote HTML documents, which at that time proved to be extraordinarily simple. All other features have been added as the Web has grown.
Looking back, can web browser software be considered essential in the history of computing? “If we consider that we are talking about the whole package of technologies associated with access to the content of the Web, we are without doubt a milestone in the history of access to information, in addition to the more obvious display of a revolution on a scale, scope and depth that has not yet been completed (and that may never be),” replies Thomas Bruce, creator of the first web browser for Microsoft Windows, called Cello. Indeed, it is difficult to assess this revolution because we are still immersed in it. “Any browser–and, in general, any software–is only one point in a current of technical developments,” qualifies Bruce. “I hope that in the future someone can analyze the events and clearly identify the period in which the ‘browser revolution’ occurred, but at least fifty years will have to pass and currently only half the time has elapsed,” he reflects.
Although this is not a finished story, one can still speak of some key indisputable milestones, starting with the creation of WorldWideWeb, the pioneering browser with which Berners-Lee surprised the world in 1991. In 1992, Erwise and ViolaWWW made their appearance, developed in Finland and California, respectively, in 1992, for the UNIX operating system, and which became the first graphical browsers. That same year, at the University of Kansas, a “text-only” browser called Lynx was launched to distribute campus information. And since it had an interface that could read written text aloud, it enjoyed great fame among the blind. The next browser to turn up was Midas, designed for physicists to exchange information about their research.

Mosaic burst into the Mac a year later as the first “popular” graphical browser, which would allow any user to surf the net with just a click and that, for the first time, inserted images into the text. Then it was the turn of Arena, whose novelty was that it allowed background images, tables and formulas, and mathematical expressions. The first browser for Microsoft Windows was the aforementioned Cello, written in 1993 by Bruce for the Legal Information Institute at Cornell University Law School (USA) in order to provide access to legal information, since the most lawyers were users of Windows, not Unix or Mac. Cello incorporated support for protocols other than web pages, such as FTP for file sharing, or Gopher for the search and retrieval of documents.
In view of the success that programs designed for surfing the Internet were beginning to enjoy, it didn’t take long for IBM to create its own browser, WebExplorer. In 1994, the famous Netscape made its appearance, followed in 1995 by Internet Explorer, its closest competitor. Opera came soon after, ahead of Grail, the first browser “hackable” by researchers. Arachne (1996) was designed for computers using MS-DOS or OpenDOS, and Amaya, with free software that would enable immediate editing of any page. The list of browsers is completed with Konqueror (1996), Galeon (2001), Safari (2003) from Apple, Firefox (2004) and Chrome (2008) from Google, the youngest of the family.

In all cases, promoting access to information has been the leitmotif of the developers who have been involved in the development of these applications. “Most of the time the advance in browsers has been guided by one question: what can I do to make it easier for people to access anything they want to know?” says Bruce Thomas. In this regard, and with the network of networks cluttered with information, it seems that opting for the semantic web will be key. This trend, promoted by the inventor of the Web himself, intends to apply artificial intelligence to the Internet so that machines can understand online content and help us navigate by locating, classifying, providing structure and integrating all this information that, so far, forms a teeming mountain of unorganized data.
At this point, the web has become what Bruce defines as “a huge number of information transactions, often inconsequential.” “Right now there is someone out there using the Internet to find a mechanic for his car, someone using it to decide whether to take her child to the doctor, someone who is writing a song with someone else thousands of kilometers away, another person is surfing to acquire a work of art by an artist who they would not have learned about without the Internet, more than one person is doing business, many others are educating themselves…” notes the researcher. The impact that all this is having is difficult to quantify. “Computing has always been about quantitative improvements leading to huge qualitative changes; it is not about assessing the extent to which the web–and the browsers–have changed our world, but rather that, in many ways, the web now IS our world,” concludes Bruce.
Comments on this publication