From anywhere and with just a mobile phone, anyone can become an air traffic controller, or at least a virtual air traffic controller. One can follow the world traffic flow of airplanes live and find out where an aircraft is coming from and where it is headed. One just has to take advantage of the millions of pieces of data that fly across the Internet. This is the magic power of Big Data. Artificial intelligence then enters the picture to find patterns and give meaning to the massive and heterogeneous information stream. Together, these two technologies have embarked on a colossal mission far removed from their usual commercial applications: finding treatments for diseases such as cancer.

When Regina Barzilay, a computer scientist at the Massachusetts Institute of Technology (MIT), was diagnosed with breast cancer, she not only lost her personal life, but it also turned her research upside down. In the endless shuffling between hospitals, she realised that most of the information being recorded about patients was not being used. “Clinical decisions are often based on clinical trials, that is, on the 3% of patients participating in them. This means that the entire experience of what happens to 97% of the patients is not being used. How would Amazon work if it discarded 97% of the data? I think we are sitting on a gold mine of data that we are not using,” she maintained during a visit to Madrid as a jury member of the BBVA Foundation Frontiers of Knowledge Award.
Barzilay specializes in teaching natural language to machines, teaching those that only understand ones and zeros to read and write in our language. So, she decided to put aside the rest of her projects and focus on teaching these smart devices to read the notes that doctors write in their pathology reports, in order to transfer them to a data table where they could be searched for information. This way, if a patient has breast cancer and has to receive a treatment, the database can first be checked to see what treatments other women with the same tumour have received and how they reacted to them. There was no reason to start from scratch. “We had better technology to recommend a lipstick than to help you to prevent breast cancer. That had to be changed,” says the MIT researcher.
Genetic Big Data
One of the most important discoveries that the extensive decades-long research into cancer has brought us is that it is not just one disease, but many different diseases, numbering more than 200. There is no single liver cancer, nor is there a single type of pancreatic tumour. The origin of the cancer in each patient has its own causes, its own combination of genetic mutations. For this reason, treatments would be more effective if they were as personalised as the disease. This precision medicine is what the sequencing and analysis of the genome is directing us towards.

If you know exactly in which genes the cancer-causing mutations have occurred, treatment can be more precise, more certain. “It is possible to know what the molecular cause of your cancer is. It’s no longer just breast cancer, but we know exactly which genes are mutated and need to be targeted. The next challenge is to learn which drugs can treat each mutation,” explains Sergi Beltrán, director of the bioinformatics unit at the National Genome Analysis Centre (CNAG), the Spanish centre dedicated to this mission.
This technology has allowed experts to apply another working methodology: starting without established hypotheses and tracking mutations in all genes. Before the advent of sequencing machines and the supercomputing required by this technique, doctors had to hypothesise that a particular disease was caused by a mutation in four or five genes. The results could only be one of two: confirm it or refute it.
Today, however, researchers have an immense amount of information at their disposal. The Cancer Genome Atlas (TCGA) programme, launched in 2006 by a collaboration between the National Cancer Institute and the National Human Genome Research Institute, both in the US, has collected the molecular profiles of more than 20,000 samples from 33 types of cancer and healthy tissues from the same patients, generating more than 2.5 petabytes of data: genomic, epigenomic (chemical modifications to DNA that don’t change the sequence), transcriptomic (gene activity) and proteomic (the proteins that genes produce). In the UK, the Cancer Genome Project of the Wellcome Sanger Institute maintains its own large database, and both projects collaborate with others in the International Cancer Genome Consortium. All of this is freely available to the scientific community, which also has an extensive panel of web applications to integrate, compare and analyse the data.
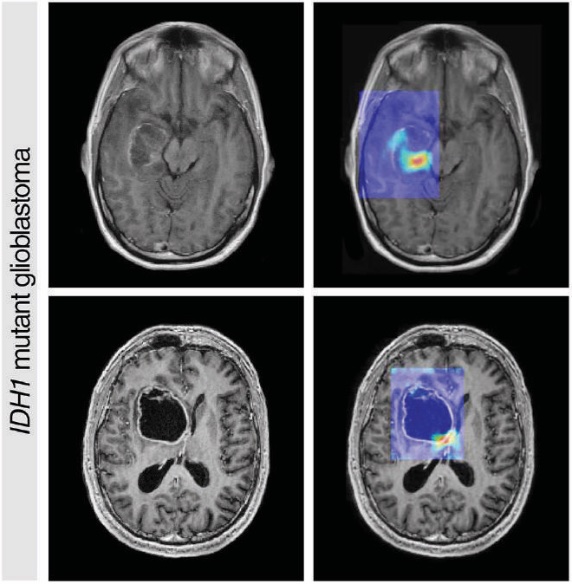
One of the applications of these studies is diagnosis. On rare occasions, not even all the tests available today are able to locate the origin of a cancer, limiting the options for treatment to generic therapies that don’t yield good results. Using TCGA data and a machine learning AI system, researchers at MIT and Yale University have been able to identify 52 cancer samples that could not be classified with standard tests, allowing targeted therapies to be applied with a better chance of success. Such tools are being used to diagnose cancers early and accurately from radiological or scan images. At MIT, Barzilay has developed algorithms that could advance the diagnosis of a cancer by one to two years, gaining critical time to apply early treatments before the tumour spreads.
A drug discovered by artificial intelligence
This new working methodology is also being applied by Niven Narain, president and co-founder of Berg, a US pharmaceutical start-up. The company has used an AI system to develop a new drug, BPM 31510, to treat pancreatic, brain, skin and other cancers. To do this, Berg collected cancerous and healthy tissue samples from 1,000 patients and processed all this data with its system, which proposed a treatment. “We’ve essentially reversed the scientific method. We allowed the biological data from the patients to lead us to the hypotheses,” Narain told Wired magazine. BPM 31510 is currently in clinical trials against several types of cancer and, according to the company, has demonstrated “anti-tumour activity with an acceptable safety profile.”
This is just one example of how AI systems are working to find new weapons against cancer, whether by proposing therapeutic targets—erroneous molecules that drive tumour growth and should be targeted—designing new drugs to neutralise them, finding new uses for known compounds in the field, or suggesting synergistic combinations of existing therapies that can improve outcomes. For example, a study in this line has revealed that the combination of vandetanib, used against thyroid cancer, and everolimus, used as an immunosuppressant in transplants and against certain cancers, could offer a possible therapy against a type of brain cancer that is currently untreatable.

The great potential of these technologies in the battle against cancer and other diseases has mobilised not only the biotech and pharmaceutical industry, but also the technology giants, who are investing in this area. Verily Life Sciences, the biomedical division of Alphabet, Google’s parent company, launched Project Baseline in 2017, which gathers health data from 10,000 people and processes it through a machine learning system to draw a large map of human health. Apple, meanwhile, is harnessing data from the millions of iPhone users who use ResearchKit and CareKit (the latter to share information directly with their doctors). The Mayo Clinic is developing a project that uses an AI algorithm to detect potential cardiovascular problems based on readings from users’ Apple Watch sensors. Microsoft is developing tiny sensors that can be worn on the skin to transmit biometric data to remote health monitors.
Cancer research is one of the biggest beneficiaries of these new technologies, but it is not the only one. Big Data and AI, combined with genetic analysis, make it possible to search for and find patterns among patients with rare diseases, who may be kilometres apart but have the same mutation. The ultimate goal is to create a huge digital library of medical data, a kind of Big Data of medicine, that respects patient privacy—data is anonymised before it is recorded —but allows for faster diagnosis and treatment. The cure for cancer is still unknown, but many are already suggesting that it lies within our data. Thanks to these new technologies and in the words of Dietmar Berger, chief medical officer and global head of development at pharmaceutical giant Sanofi, “after spending more than three decades as a hematology/oncology researcher and physician, it is invigorating to be living in and working through a “golden age” in cancer research.”
Comments on this publication