Introducción
En mi anterior entrega, “El comienzo de la era de la inteligencia artificial (IA): Parte 1”, me detuve a considerar una serie de ejemplos de programas de manipulación simbólica en IA. Dichos programas funcionan utilizando símbolos almacenados explícitamente que se manipulan lógicamente durante la ejecución del programa.

Otra clase de software de IA, denominada Redes neurales artificiales (RNA), no utiliza conocimiento explícito almacenado como reglas de funcionamiento. En su lugar, las RNA utilizan conocimiento que está codificado en parámetros numéricos –denominados pesos– y se distribuye en muchas conexiones. A diferencia de la IA simbólica, las RNA tienen características de “caja negra” ya que no pueden explicar su razonamiento de la misma forma que lo hacen los programas simbólicos de IA. No obstante, debido a sus capacidades de “aprendizaje automático”, se han convertido en el paradigma dominante de IA. El paradigma de aprendizaje que subyace en las RNA se parece mucho a la manera en que aprenden los seres humanos. Por ejemplo, debido al hecho de que la naturaleza de sus conexiones puede cambiar, muestran cierto grado de plasticidad que se traduce en que pueden adaptarse a aprender nuevas tareas. Asimismo, las RNA siguen algo que ha dado en denominarse la regla de Hebb que afirma que cada vez que se toma una decisión correcta los patrones neuronales se refuerzan. A menudo, esto se expresa diciendo que “las neuronas que se activan juntas se conectan entre sí”, lo que significa que la práctica es el camino a la perfección.
En el presente artículo, se describen brevemente las RNA artificiales y su relación con las neuronas biológicas de los seres humanos. Asimismo, se describe brevemente un ejemplo de cómo funciona una neurona artificial y la diferencia que existe entre aprendizaje supervisado y no supervisado. Finalmente, se exploran concisamente las aplicaciones de las RNA.
- Redes neurales artificiales (RNA)
Las RNA funcionan aprendiendo a partir de grandes cantidades de datos de formación. El conocimiento implícito se codifica en parámetros numéricos –denominados pesos– y se distribuye en todo el sistema. Este conocimiento implícito se codifica como decenas de miles de pesos de entrada numéricos que se calibran a medida que cada ejemplo es leído por el software. Los conceptos de RNA se modelan en relación con las tareas del cerebro biológico humano.
- La neurona biológica

El cerebro humano está compuesto por células especiales denominadas neuronas. Dichas células son especiales porque tienen ciertas partes denominadas dendritas y axones que les permiten comunicarse con otras células. Las señales se propagan de una neurona a otra mediante reacciones electroquímicas de carácter complejo. Se estima que en un cerebro humano normal hay aproximadamente 100.000 millones de neuronas. Las propias neuronas están divididas en grupos denominados redes que están estrechamente interconectados. El cerebro humano puede contemplarse como un conjunto de redes neurales. El aprendizaje se lleva a cabo utilizando una “serie de entrenamiento” de casos de ejemplo, que se analiza repetidamente para así extraer patrones de datos. Posteriormente, la red puede aplicarse a otros casos del mismo tipo en los que podrá identificar los mismos patrones y, de esta manera, podrá discriminar casos.
- El perceptrón
Una neurona individual, denominada “perceptrón”, funciona de la siguiente manera. Cada célula recibe una serie de entradas procedentes de las células vecinas y luego ajusta sus pesos (valores numéricos) para representar la fortaleza de las conexiones. Antes de que los ejemplos sean analizados, el desarrollador asigna valores iniciales a los propios pesos. Luego suma los pesos y dispara la neurona que se activa si esta suma supera un valor umbral (asignado nuevamente por el desarrollador).

En la fig. 1 podemos observar la estructura de esta neurona. Se conoce con el nombre de “perceptrón” y fue uno de los primeros conceptos de red neural que se simuló utilizando software informático. Utilizando los datos de la fig. 1., hay cuatro entradas en este ejemplo. Esto puede expresarse formalmente de la siguiente forma: dado que las entradas son x1,.…x 4 con pesos w1…w 4 entonces:
- Si x1 w1 + x2 w2+ x3 w3 + x4 w4 > y (donde y es un valor umbral, habitualmente mayor o igual a 0,5).
Entonces, la neurona se activa. El resto de neuronas no se activan
Capas
En un perceptrón, solo existe un peso para cada entrada y solo un resultado. Esto significa que un perceptrón de capa única solo puede clasificar patrones de tipo lineal. Sin entrar demasiado en detalles técnicos, esto significa que un perceptrón o bien una combinación de perceptrones conectados en una capa no proporcionarán el poder expresivo necesario para describir el modelo en el nivel correcto. Sin embargo, en una red multicapa hay muchos pesos y cada uno de ellos contribuye a más de un resultado. Esta es la razón por la cual las redes multicapa se utilizan en la resolución de problemas prácticos, ya que pueden modelar el sistema en el nivel correcto. La fig. 2 muestra un segmento de una RNA multicapa.
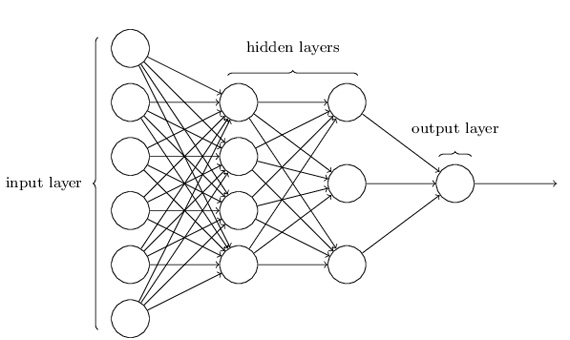
Aprendizaje supervisado
En términos generales, los algoritmos de aprendizaje supervisado funcionan de tal manera que el programador (o el desarrollador) del sistema proporciona a la RNA la respuesta correcta cuando cada ejemplo se introduce en el sistema. La RNA determina los pesos de tal manera que, una vez dados los datos de entrada, producirá el resultado deseado. Posteriormente, se introducen más ejemplos, uno a uno, con los pesos ajustados de tal manera que se produzcan resultados cercanos a lo esperado. Dada una serie de entrenamiento suficientemente extensa, se efectuará un “ajuste fino” de las entradas de tal manera que el probable resultado se pueda predecir razonablemente. Esto significa que incluso cuando el sistema se alimenta con un pequeño número de ejemplos de datos ruidosos o incompletos, su impacto será reducido y, por tanto, se preservará la solidez de la RNA. En este ejemplo, el aprendizaje supervisado funciona proporcionando cada fila de datos, incluyendo la columna de resultados para la serie de entrenamiento y comparando el resultado esperado con el resultado real. Posteriormente, los pesos se ajustan de tal manera que los resultados reales se acercarán a los resultados esperados. Pero resulta necesario indicar valores iniciales para los pesos y debe asignarse un valor para efectuar la comparación con el resultado, al tiempo que debe escogerse un valor para la cantidad mediante la cual los valores de peso deben ajustarse cuando resulta necesario.
Aprendizaje no supervisado
Con el aprendizaje no supervisado, la RNA solo recibe los datos de entrada, sin recibir información acerca del resultado esperado. En esta clase de aprendizaje, la RNA aprende a producir el patrón de idea. Aprendizaje profundo los algoritmos constituyen un fenómeno desarrollado muy recientemente que pueden realizar esto a través de una combinación de muchos ejemplos y varias capas de red, requiriendo una gran cantidad de potencia informática. El aumento del uso de técnicas de “big data” hace que lo anterior resulte posible, ya que los datos pueden extraerse de muchas fuentes a diario, como es el caso de las redes sociales, la venta al por menor, el comercio, etc., en formatos tales como sonido, texto e imágenes. Esto significa que, por ejemplo, las redes pueden proporcionar imágenes, sin saber demasiado sobre ellas, y pueden descubrir características por sí mismas (en lugar de que se les tenga que decir en qué consisten dichas características, como puede ser el caso de los bordes de un objeto físico). En lugar de que el desarrollador identifique las características, se entrena a la red alimentándola con datos y puntuando su desempeño. La red utiliza capas de nodos que buscan características en distintos niveles de abstracción. Los sistemas de aprendizaje profundo se denominan así porque los algoritmos de aprendizaje operan en varias capas (profundas). Cada capa procesa datos procedentes de la capa precedente, cuyo resultado pasa a la siguiente capa. El número de capas puede variar. Por ejemplo, GoogleNet utiliza 22 capas en sus sistemas de visión informática para el reconocimiento de objetos. En los últimos años, los sistemas de aprendizaje profundo han tenido un gran impacto en el campo de la IA.
Aplicaciones de las RNA
La tecnología de las RNA se ha utilizado con éxito durante muchos años. Durante los últimos veinte años, las aplicaciones utilizadas habitualmente han sido los programas para detectar correos spam, aprobar aplicaciones para hipotecas y préstamos y aplicaciones para realizar diagnósticos médicos. Estas aplicaciones utilizan algoritmos de aprendizaje supervisado. El éxito de las RNA se deriva de la forma en que suelen aportar ideas más allá de las capacidades humanas, como es el caso del reconocimiento de patrones que solo resulta posible mediante análisis de aprendizaje automático. Por ejemplo, el Chase Manhattan Bank utilizó una RNA para examinar datos acerca del uso de tarjetas de crédito robadas. En este sentido, descubrieron que las ventas más sospechosas se producían en el caso de los zapatos de mujer con precios situados entre 40 y 80 dólares estadounidenses. Esta es una de las aplicaciones de las RNA que intentan extraer valor a partir de las bases de datos. Se trata de una actividad denominada “minería de datos”. Esto se realiza descubriendo patrones en los datos, lo que conduce a mejorar la toma de decisiones. Las técnicas de minería de datos se utilizan frecuentemente en otras áreas de venta al por menor. Por ejemplo, el Análisis de la cesta de la compra (MBA) es una técnica que se basa en la teoría que afirma que los clientes que adquieren ciertos grupos de productos son más propensos a comprar otro tipo de productos. Cuando se detecta dicha información cabe interpretarla en el sentido de que al vendedor al por menor puede interesarle cambiar el diseño de la tienda, de tal forma que dichos productos estén a mano para aumentar las ventas.

No obstante, en los últimos años, las RNA que utilizan algoritmos no supervisados han tenido un gran impacto en el campo de la IA. Se están utilizando RNA de aprendizaje profundo en distintos dominios, incluyendo las aplicaciones médicas de reconocimiento de imágenes, los coches autónomos y la robótica. Entre los usos más destacados se incluyen los programas inteligentes de asistencia personal para teléfonos inteligentes, como es el caso de Alexa de Amazon, Cortana de Microsoft y Siri de Apple. Sus características varían, pero habitualmente reconocen datos de voz y permiten la interacción, la reproducción de música o la configuración de recordatorios, al tiempo que proporcionan enlaces de voz a los contactos de la base de datos de clientes, etc. Por otro lado, se dice que Apple está incorporando un chip de IA dedicado en su próxima generación de teléfonos inteligentes. Esto significa que el comportamiento del usuario individual puede ser aprendido, lo cual puede traducirse en mejoras en la duración de la batería y el rendimiento del dispositivo. Las RNA de aprendizaje profundo constituyen un campo que está creciendo rápidamente con aplicaciones que, en los próximos años, probablemente sean de uso muy extendido.
Comentarios sobre esta publicación