A large-scale attack calls for a total response on all fronts, and this is how humanity is reacting to the pandemic of SARS-CoV-2, which causes COVID-19. In the open warfare against this powerful enemy, the first and most visible line of defence is that of medicines and healthcare workers. In a second line, the biology laboratories are fighting against the clock to understand the intricacies of the virus and develop treatments or vaccines. But in the battle plans against the coronavirus there is another front that is no less essential in our technological age: Big Data and its processing through Artificial Intelligence (AI) and automatic learning systems, which are proving to be essential weapons in the battle against the virus. Here we review some examples of this.
Improving epidemiological models
Mathematical models have been an indispensable tool for monitoring and predicting the evolution of epidemics since 1854, when Englishman John Snow mapped London and used statistics to pinpoint the outbreak of cholera to a public water pump. However, epidemiologists insist that models are not crystal balls for predicting the future, but offer a comparison between probable ranges of results according to the different values of the variables that are introduced as inputs. Nevertheless, their importance is key, as they guide the policies to be adopted.

The most classic models are the so-called SIR (Susceptible-Infectious-Recovered) or SEIR (adding the category of Exposed) models. Computing has enabled the development of other more sophisticated ones called agent-based models, which can simulate the actions and interactions of millions of people. But even with the most complex models, there are still many unknowns surrounding the new virus. The pandemic has put models at the centre of the scientific debate, so some experts have called for the computer code of all these models to be published in open source in digital repositories. Several institutions have already done so, which will help the scientific community to improve the models.
Coronavirus tracking apps
The first successes in the initial containment of the pandemic have been achieved in places where selective technological tracking of infected persons and the tracing of their movements and contacts has been carried out using data from mobile phones, credit cards and security cameras, rather than imposing drastic confinement measures on the entire population. One example is South Korea, a country that, unlike others, had a recent and updated plan against epidemics, put together after the Middle East Respiratory Syndrome (MERS) outbreak in 2015.

While Korea’s strategy was praised, it also generated controversy because of privacy concerns. However, without minimizing the ethical debate, initiatives have begun to emerge in the rest of the world that seek to harness this technological potential. Numerous approaches of this type are already underway. In April, tech giants Apple and Google announced the joint creation of a system that will operate on iOS and Android via Bluetooth. Although these new apps are less intrusive than the Korean option, being anonymous, voluntary and not designed to report to authorities, potential privacy issues are still being debated. But in addition, experts are wondering whether they will contribute to raising undue alarm.
AI to Help Researchers Find the Most Relevant Studies
The severity of the pandemic has prompted an explosive growth in scientific studies about the virus and its disease. According to Science magazine, more than 23,000 papers have been published since January, a figure that is doubling every 20 days. The CORD-19 data set, a project promoted by the Allen Institute for AI in collaboration with other institutions, is an attempt to bring together everything that has been published; however, with more than 63,000 records, the avalanche of material would be completely unmanageable for scientists. For this reason, CORD-19 has a customizable AI search system so that each scientist can find the research most relevant to their interests. Other platforms such as COVIDScholar pursue similar goals, and Scite.ai helps scientists know whether findings have been supported or contradicted by subsequent studies.
Machines that search for treatments
Given that potential new drugs for SARS-CoV-19 will have to wait years for approval, many researchers are working on a potentially more immediate avenue: the repositioning of existing drugs, already approved for other indications, that may show some efficacy against SARS-CoV-2. Remdesivir, the only drug that has so far exhibited some real promise, was created against another virus, Ebola, so it was a clear candidate. Several research teams are testing other possible treatments based on their known mechanisms of action or their interactions with proteins in the virus. But how can we identify other promising treatment possibilities when nothing is known about these compounds that suggests any possible effectiveness against the virus?
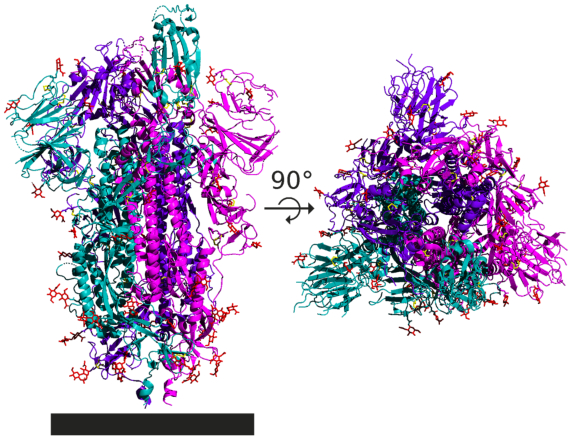
Scientists are employing neural networks to identify possible interactions between virus proteins and existing drugs. They are using systems such as DeepMind’s AlphaFold, which is based on neural networks and predicts the 3D structure of SARS-CoV-2 proteins. From these models a virtual docking can be done, which is a prediction of the protein’s physical interaction with drugs. This says nothing about any potential beneficial effects with respect to treatments; these virtual interactions must first be confirmed in the laboratory and then their effects on the biology of the virus and the organism itself must be studied. But these leads have already identified a number of potential candidate compounds, which several groups are now working on.
Data to predict the behaviour of the virus or its effects
The immense amount of scientific data being collected worldwide is a treasure trove of invaluable information for unlocking the secrets of the virus and its disease. The COVID Human Genetic Effort is an international consortium involving dozens of centres around the world, which gathers genetic data from patients in an attempt to identify by computer analysis which gene variants could be associated with a more severe course of the disease or, conversely, with an asymptomatic infection. Something similar is being pursued by the COVID-19 Host Genetics Initiative. For their part, researchers at the University of Toronto (Canada) have collected and analysed data on more than 375,000 confirmed cases of COVID-19 from 144 different regions of the world to determine whether there are differences in the behaviour of the virus depending on latitude, temperature and environmental humidity, one of the great unknowns of the pandemic. The results indicate only a possible mild sensitivity of the virus to humidity.
Javier Yanes
Comments on this publication